 Linux Load Balancing Cluster HowTo is a document that describes how you can create a failover cluster of Linux machines that acts as a load balancing mechanism between the real network and groups of other machines (real servers).
Linux Load Balancing Cluster HowTo is a document that describes how you can create a failover cluster of Linux machines that acts as a load balancing mechanism between the real network and groups of other machines (real servers).
This setup will help someone to achieve high availability in many services plus the ability and flexibility to add / remove servers when needed.
With the combination of some great tools like ipvs (Kernel Module for Virtual Servers), Linux HA (Heartbeat – great tool for Linux clustering), Ldirectord (the monitor / failover tool for ipvs), Ganglia (a great cluster toolkit that measures performance) and some custom tools that used in order to achieve session affinity (Layer 4 Load Balancing) and session replication / syslog alerting.
“In computing, load balancing is a technique used to spread work load among many processes, computers, networks, disks or other resources, so that no single resource is overloaded.

One way to archive this is by using the technique of virtual servers. Virtual server is a highly scalable and highly available server built on a cluster of real servers. The architecture of server cluster is fully transparent to end users, and the users interact with the system as if it were only a single high-performance virtual server.
Build a high-performance and highly available server using clustering technology, which provides good scalability, reliability and availability.
- 2 Linux servers as load balancers with 2 network interfaces both (balancer1 – eth0:10.0.0.3 and eth1:10.10.10.3 and balancer2 – eth0:10.0.0.5 and eth1:10.10.10.5).
- 2 Linux servers that will serve web, ftp, pop and smtp services (linux1-10.0.0.10 and linux2-10.0.0.20).
- 2 Windows servers that will serve web, ftp services (windows1-10.0.0.50 and windows2-10.0.0.60).
The image below shows how we interconnect them and prepare their networks for the cluster installation. In the example we used Linux Redhat Enterprise for the load balancers with custom compiled 2.6.7 kernel and custom compiled ipvsadm / linux-ha, but the installation of all the components must be pretty much the same for all linux distributions.
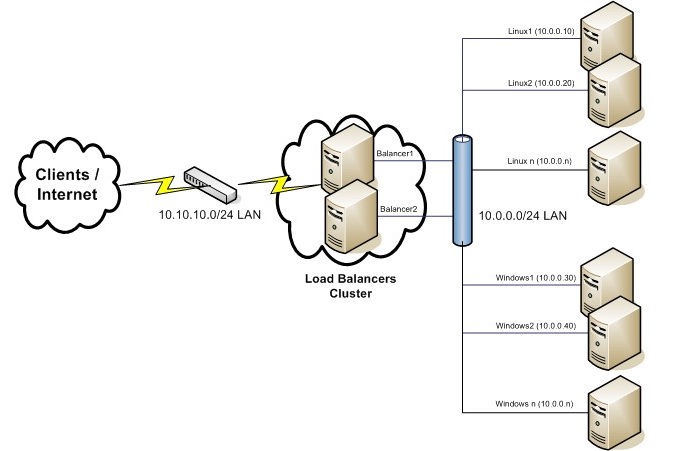
Load Balancers Setup
We recommend a minimal linux installation, with only the desired packages installed. You also need most of development packages in order to successfully compile everything you need.
For the kernel 2.6.x compilation be sure that you have these options:
Code maturity level options --->
[*] Prompt for development and/or incomplete code/drivers
Networking options --->
IP: Netfilter Configuration --->
[*] Network packet filtering (replaces ipchains)
[ ] Network packet filtering debugging
<M> Connection tracking (required for masq/NAT)
<M> FTP protocol support
<M> IP tables support (required for filtering/masq/NAT)
<M> Packet filtering
<M> REJECT target support
<M> Full NAT
<M> MASQUERADE target support
<M> REDIRECT target support
...
IP: Virtual Server Configuration --->
<M> IP virtual server support (EXPERIMENTAL)
[ ] IP virtual server debugging
(16) IPVS connection table size (the Nth power of 2)
--- IPVS transport protocol load balancing support
[*] TCP load balancing support
[*] UDP load balancing support
[*] ESP load balancing support
[*] AH load balancing support
--- IPVS scheduler
<M> round-robin scheduling
<M> weighted round-robin scheduling
<M> least-connection scheduling
<M> weighted least-connection scheduling
<M> locality-based least-connection scheduling
<M> locality-based least-connection with replication scheduling
<M> destination hashing scheduling
<M> source hashing scheduling
<M> shortest expected delay scheduling
<M> never queue scheduling
--- IPVS application helper
<M> FTP protocol helper
To make the load balancers forward the masquerading packets
# echo 1 > /proc/sys/net/ipv4/ip_forward
# cat /proc/sys/net/ipv4/ip_forward
or to have this option permanently we can add in /etc/sysctl.conf
# Controls IP packet forwarding
net.ipv4.ip_forward = 1
After we compile the kernel and reboot with these modules / options enabled, we can start compile linux-ha cluster:
(Download from http://linux-ha.org/download/index.html )
# wget http://linux-ha.org/download/heartbeat-1.2.3.tar.gz
# tar zxvf heartbeat-1.2.3.tar.gz
# cd heartbeat-1.2.3
# ./ConfigureMe configure
# make
# make install
For heartbeat configuration we need to change 3 configuration files:
- /etc/ha.d/authkeys
- /etc/ha.d/haresources
- /etc/ha.d/ha.cf
Here is an example for each one:
/etc/ha.d/authkeys :
#
# Authentication file. Must be mode 600
#
#
# Must have exactly one auth directive at the front.
# auth send authentication using this method-id
#
# Then, list the method and key that go with that method-id
#
# Available methods: crc sha1, md5. Crc doesn't need/want a key.
#
# You normally only have one authentication method-id listed in this file
#
# Put more than one to make a smooth transition when changing auth
# methods and/or keys.
#
#
# sha1 is believed to be the "best", md5 next best.
#
# crc adds no security, except from packet corruption.
# Use only on physically secure networks.
#
auth 1
#1 crc
#2 sha1 HI!
#3 md5 Hello!
1 sha1 TestLinuZ
/etc/ha.d/ha.cf :
#
# There are lots of options in this file. All you have to have is a set
# of nodes listed {"node ...}
# and one of {serial, bcast, mcast, or ucast}
#
# ATTENTION: As the configuration file is read line by line,
# THE ORDER OF DIRECTIVE MATTERS!
#
# In particular, make sure that the timings and udpport
# et al are set before the heartbeat media are defined!
# All will be fine if you keep them ordered as in this
# example.
#
#
# Note on logging:
# If any of debugfile, logfile and logfacility are defined then they
# will be used. If debugfile and/or logfile are not defined and
# logfacility is defined then the respective logging and debug
# messages will be loged to syslog. If logfacility is not defined
# then debugfile and logfile will be used to log messges. If
# logfacility is not defined and debugfile and/or logfile are not
# defined then defaults will be used for debugfile and logfile as
# required and messages will be sent there.
#
# File to write debug messages to
debug 1
debugfile /var/log/ha-debug
#
#
# File to write other messages to
#
logfile /var/log/ha-log
#
#
# Facility to use for syslog()/logger
#
logfacility local0
#
#
# A note on specifying "how long" times below...
#
# The default time unit is seconds
# 10 means ten seconds
#
# You can also specify them in milliseconds
# 1500ms means 1.5 seconds
#
#
# keepalive: how long between heartbeats?
#
keepalive 2
#
# deadtime: how long-to-declare-host-dead?
#
deadtime 60
#
# warntime: how long before issuing "late heartbeat" warning?
# See the FAQ for how to use warntime to tune deadtime.
#
warntime 40
#
#
# Very first dead time (initdead)
#
# On some machines/OSes, etc. the network takes a while to come up
# and start working right after you've been rebooted. As a result
# we have a separate dead time for when things first come up.
# It should be at least twice the normal dead time.
#
initdead 120
#
#
# nice_failback: determines whether a resource will
# automatically fail back to its "primary" node, or remain
# on whatever node is serving it until that node fails.
#
# The default is "off", which means that it WILL fail
# back to the node which is declared as primary in haresources
#
# "on" means that resources only move to new nodes when
# the nodes they are served on die. This is deemed as a
# "nice" behavior (unless you want to do active-active).
#
nice_failback on
#auto_failback off
#
# hopfudge maximum hop count minus number of nodes in config
#hopfudge 1
#
#
# Baud rate for serial ports...
# (must precede "serial" directives)
#
#baud 19200
#
# serial serialportname ...
#serial /dev/ttyS0 # Linux
#serial /dev/cuaa0 # FreeBSD
#serial /dev/cua/a # Solaris
#
# What UDP port to use for communication?
# [used by bcast and ucast]
#
udpport 694
#
# What interfaces to broadcast heartbeats over?
#
#bcast eth0 # Linux
bcast eth1
#bcast eth1 eth2 # Linux
#bcast le0 # Solaris
#bcast le1 le2 # Solaris
#
# Set up a multicast heartbeat medium
# mcast [dev] [mcast group] [port] [ttl] [loop]
#
# [dev] device to send/rcv heartbeats on
# [mcast group] multicast group to join (class D multicast address
# 224.0.0.0 - 239.255.255.255)
# [port] udp port to sendto/rcvfrom (no reason to differ
# from the port used for broadcast heartbeats)
# [ttl] the ttl value for outbound heartbeats. This affects
# how far the multicast packet will propagate. (1-255)
# [loop] toggles loopback for outbound multicast heartbeats.
# if enabled, an outbound packet will be looped back and
# received by the interface it was sent on. (0 or 1)
# This field should always be set to 0.
#
#
mcast eth1 225.0.0.1 694 1 0
#
# Set up a unicast / udp heartbeat medium
# ucast [dev] [peer-ip-addr]
#
# [dev] device to send/rcv heartbeats on
# [peer-ip-addr] IP address of peer to send packets to
#
#ucast eth1 10.0.0.3
#
#
# Watchdog is the watchdog timer. If our own heart doesn't beat for
# a minute, then our machine will reboot.
#
#watchdog /dev/watchdog
#
# "Legacy" STONITH support
# Using this directive assumes that there is one stonith
# device in the cluster. Parameters to this device are
# read from a configuration file. The format of this line is:
#
# stonith <stonith_type> <configfile>
#
# NOTE: it is up to you to maintain this file on each node in the
# cluster!
#
#stonith baytech /etc/ha.d/conf/stonith.baytech
#
# STONITH support
# You can configure multiple stonith devices using this directive.
# The format of the line is:
# stonith_host <hostfrom> <stonith_type> <params...>
# <hostfrom> is the machine the stonith device is attached
# to or * to mean it is accessible from any host.
# <stonith_type> is the type of stonith device (a list of
# supported drives is in /usr/lib/stonith.)
# <params...> are driver specific parameters. To see the
# format for a particular device, run:
# stonith -l -t <stonith_type>
#
#
# Note that if you put your stonith device access information in
# here, and you make this file publically readable, you're asking
# for a denial of service attack ;-)
#
#
#stonith_host * baytech 10.0.0.3 mylogin mysecretpassword
#stonith_host ken3 rps10 /dev/ttyS1 kathy 0
#stonith_host kathy rps10 /dev/ttyS1 ken3 0
#
# Tell what machines are in the cluster
# node nodename ... -- must match uname -n
node balancer1
node balancer2
#node ken3
#node kathy
#
# Less common options...
#
# Treats 10.10.10.254 as a psuedo-cluster-member
#
# ping 10.0.0.1
#
# Started and stopped with heartbeat. Restarted unless it exits
# with rc=100
#
#respawn userid /path/name/to/run
apiauth ipfail uid=hacluster
/etc/ha.d/haresources:
#
# This is a list of resources that move from machine to machine as
# nodes go down and come up in the cluster. Do not include
# "administrative" or fixed IP addresses in this file.
#
# <VERY IMPORTANT NOTE>
# The haresources files MUST BE IDENTICAL on all nodes of the cluster.
#
# The node names listed in front of the resource group information
# is the name of the preferred node to run the service. It is
# not necessarily the name of the current machine. If you are running
# nice_failback OFF then these services will be started
# up on the preferred nodes - any time they're up.
#
# If you are running with nice_failback ON, then the node information
# will be used in the case of a simultaneous start-up.
#
# BUT FOR ALL OF THESE CASES, the haresources files MUST BE IDENTICAL.
# If your files are different then almost certainly something
# won't work right.
# </VERY IMPORTANT NOTE>
#
#
# We refer to this file when we're coming up, and when a machine is being
# taken over after going down.
#
# You need to make this right for your installation, then install it in
# /etc/ha.d
#
# Each logical line in the file constitutes a "resource group".
# A resource group is a list of resources which move together from
# one node to another - in the order listed. It is assumed that there
# is no relationship between different resource groups. These
# resource in a resource group are started left-to-right, and stopped
# right-to-left. Long lists of resources can be continued from line
# to line by ending the lines with backslashes ("\").
#
# These resources in this file are either IP addresses, or the name
# of scripts to run to "start" or "stop" the given resource.
#
# The format is like this:
#
#node-name resource1 resource2 ... resourceN
#
#
# If the resource name contains an :: in the middle of it, the
# part after the :: is passed to the resource script as an argument.
# Multiple arguments are separated by the :: delimeter
#
# In the case of IP addresses, the resource script name IPaddr is
# implied.
#
# For example, the IP address 135.9.8.7 could also be represented
# as IPaddr::135.9.8.7
#
# THIS IS IMPORTANT!! vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv
#
# The given IP address is directed to an interface which has a route
# to the given address. This means you have to have a net route
# set up outside of the High-Availability structure. We don't set it
# up here -- we key off of it.
#
# The broadcast address for the IP alias that is created to support
# an IP address defaults to the highest address on the subnet.
#
# The netmask for the IP alias that is created defaults to the same
# netmask as the route that it selected in in the step above.
#
# The base interface for the IPalias that is created defaults to the
# same netmask as the route that it selected in in the step above.
#
# If you want to specify that this IP address is to be brought up
# on a subnet with a netmask of 255.255.255.0, you would specify
# this as IPaddr::135.9.8.7/24 .
#
# If you wished to tell it that the broadcast address for this subnet
# was 135.9.8.210, then you would specify that this way:
# IPaddr::135.9.8.7/24/135.9.8.210
#
# If you wished to tell it that the interface to add the address to
# is eth0, then you would need to specify it this way:
# IPaddr::135.9.8.7/24/eth0
#
# And this way to specify both the broadcast address and the
# interface:
# IPaddr::135.9.8.7/24/eth0/135.9.8.210
#
# The IP addresses you list in this file are called "service" addresses,
# since they're they're the publicly advertised addresses that clients
# use to get at highly available services.
#
# For a hot/standby (non load-sharing) 2-node system with only
# a single service address,
# you will probably only put one system name and one IP address in here.
# The name you give the address to is the name of the default "hot"
# system.
#
# Where the nodename is the name of the node which "normally" owns the
# resource. If this machine is up, it will always have the resource
# it is shown as owning.
#
# The string you put in for nodename must match the uname -n name
# of your machine. Depending on how you have it administered, it could
# be a short name or a FQDN.
#
#-------------------------------------------------------------------
#
# Simple case: One service address, default subnet and netmask
# No servers that go up and down with the IP address
#
#just.linux-ha.org 135.9.216.110
#
#-------------------------------------------------------------------
#
# Assuming the adminstrative addresses are on the same subnet...
# A little more complex case: One service address, default subnet
# and netmask, and you want to start and stop http when you get
# the IP address...
#
#just.linux-ha.org 135.9.216.110 http
#-------------------------------------------------------------------
#
# A little more complex case: Three service addresses, default subnet
# and netmask, and you want to start and stop http when you get
# the IP address...
#
#just.linux-ha.org 135.9.216.110 135.9.215.111 135.9.216.112 httpd
#-------------------------------------------------------------------
#
# One service address, with the subnet, interface and bcast addr
# explicitly defined.
#
#just.linux-ha.org 135.9.216.3/28/eth0/135.9.216.12 httpd
#
#-------------------------------------------------------------------
#
# An example where a shared filesystem is to be used.
# Note that multiple aguments are passed to this script using
# the delimiter '::' to separate each argument.
#
#node1 10.0.0.170 Filesystem::/dev/sda1::/data1::ext2
#
# Regarding the node-names in this file:
#
# They must match the names of the nodes listed in ha.cf, which in turn
# must match the `uname -n` of some node in the cluster. So they aren't
# virtual in any sense of the word.
#
balancer1 10.10.10.100 10.10.10.110 10.0.0.1 ldirectord
Remember to add a user hacluster and a group haclient:
# groupadd -g 150 haclient
# useradd -s /sbin/nologin -d /home/hacluster -g 150 -u 150 hacluster
With this set up we have 3 Cluster IPs for the virtual servers: 10.10.10.100 – Linux Virtual server, 10.10.10.110 – Windows Virtual server, 10.0.0.1 – This must be the default gateway for all real servers. We also assign ldirectord to start in the active node. In order to have ldirectord started, we need an init script in /etc/ha.d/resource.d directory. We can simply do this:
# ln -s /etc/init.d/ldirectord /etc/ha.d/resource.d/ldirectord
(Or you can copy /etc/init.d/ldirectord to /etc/ha.d/resource.d/ldirectord).
Here is /etc/ha.d/ldirectord.cf:
#
# Sample ldirectord configuration file to configure various virtual services.
#
# Ldirectord will connect to each real server once per second and request
# /index.html. If the data returned by the server does not contain the
# string "Test Message" then the test fails and the real server will be
# taken out of the available pool. The real server will be added back into
# the pool once the test succeeds. If all real servers are removed from the
# pool then localhost:80 is added to the pool as a fallback measure.
# Global Directives
checktimeout=5
checkinterval=5
#fallback=127.0.0.1:80
autoreload=yes
logfile="/var/log/ldirectord.log"
#logfile="local0"
quiescent=no
# Linux WebServers
virtual=10.10.10.100:80
real=10.0.0.10:80 masq 1
real=10.0.0.20:80 masq 1
# real=192.168.6.6:80 gate
# fallback=127.0.0.1:80 gate
service=http
request="/test.html"
receive="test page"
# virtualhost=test1.syslog.gr
scheduler=wlc
persistent=30
netmask=255.255.255.0
protocol=tcp
# Linux FTP Server
virtual=10.10.10.100:21
real=10.0.0.10:21 masq 1
real=10.0.0.10:21 masq 1
# real=192.168.16.5:21 masq
# fallback=127.0.0.1:21
service=ftp
scheduler=wrr
#request="message.txt"
#receive="ftpserver"
login="testuser1"
passwd="testpass"
persistent=300
netmask=255.255.255.0
protocol=tcp
checktype=negotiate
# Linux SMTP
virtual=10.10.10.100:25
real=10.0.0.10:25 masq 1
real=10.0.0.20:25 masq 1
# fallback=127.0.0.1:25
service=smtp
scheduler=wlc
receive="220"
# persistent=600
protocol=tcp
# Linux POP
virtual=10.10.10.100:110
real=10.0.0.10:110 masq 1
real=10.0.0.20:110 masq 1
# fallback=127.0.0.1:110
service=pop
scheduler=wlc
receive="+OK"
persistent=600
protocol=tcp
# Windows WebServers
virtual=10.10.10.110:80
real=10.0.0.50:80 masq 1
real=10.0.0.60:80 masq 1
# real=192.168.6.6:80 gate
# fallback=127.0.0.1:80 gate
service=http
request="/test.html"
receive="test page"
# virtualhost=test2.syslog.gr
scheduler=wlc
persistent=30
netmask=255.255.255.0
protocol=tcp
# Windows FTP Server
virtual=10.10.10.110:21
real=10.0.0.50:21 masq 1
real=10.0.0.60:21 masq 1
# real=192.168.16.5:21 masq
# fallback=127.0.0.1:21
service=ftp
scheduler=wrr
#request="message.txt"
#receive="ftpserver"
login="testuser2"
passwd="testpass2"
persistent=300
netmask=255.255.255.0
protocol=tcp
checktype=negotiate
This ldirectord.cf requires these:
- 1 page test.html in virtual host test1.syslog.gr that contains the string “test page” on both linux servers.
- 1 page test.html in virtual host test2.syslog.gr that contains the string “test page” on both windows servers.
- 1 user testuser1 with password testpass that can login to linux ftp servers.
- 1 user testuser2 with password testpass that can login to windows ftp servers.
- SMTP Service in linux response with a string starting with “220 “
- POP Service in linux response with a string starting with “+OK “
If this does not work try this https://www.syslog.gr/images/downloads/ipvs-1.1.7.tar.gz
# wget http://www.linuxvirtualserver.org/software/kernel-2.5/ipvs-1.1.7.tar.gz
# tar zxvf ipvs-1.1.7.tar.gz
# cd ipvs-1.1.7/ipvs/ipvsadm
# make
# make install
If this compiles ok you can now see/administer ipvs through the command ipvsadm.
For example:
# /sbin/ipvsadm -Ln
IP Virtual Server version 1.2.0 (size=65536)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.10.10.100:80 wlc
-> 10.0.0.10:80 Masq 1 0 0
-> 10.0.0.20:80 Masq 1 0 0
TCP 10.10.10.100:21 wlc
-> 10.0.0.10:21 Masq 1 0 0
-> 10.0.0.20:21 Masq 1 0 0
TCP 10.10.10.100:110 wlc
-> 10.0.0.10:110 Masq 1 0 0
-> 10.0.0.20:110 Masq 1 0 0
TCP 10.10.10.100:25 wlc
-> 10.0.0.10:25 Masq 1 0 0
-> 10.0.0.20:25 Masq 1 0 0
TCP 10.10.10.110:80 wlc
-> 10.0.0.50:80 Masq 1 0 0
-> 10.0.0.60:80 Masq 1 0 0
TCP 10.10.10.110:21 wlc
-> 10.0.0.50:21 Masq 1 0 0
-> 10.0.0.60:21 Masq 1 0 0
In order for the replies to return to the original source, a packet masquerade must be done. You can archive this using the command:
# iptables –table nat –append POSTROUTING -s 10.0.0.0/24 -j MASQUERADE
An example of full /etc/sysconfig/iptables configuration is shown below (you can easily convert it to iptables commands):
# FireWall / Masquerade / Routing Config 4 IPTables
# Written by: Avatar
*nat
:PREROUTING ACCEPT [0:0]
:POSTROUTING ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A POSTROUTING -s 10.0.0.0/255.255.255.0 -j MASQUERADE
COMMIT
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
:HA-INPUT - [0:0]
-A INPUT -j HA-INPUT
-A FORWARD -j HA-INPUT
# Invalid
-A HA-INPUT -m state --state INVALID -j DROP
# Trusted
-A HA-INPUT -i lo -j ACCEPT
-A HA-INPUT -i eth1 -j ACCEPT
-A HA-INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
# WEB
-A HA-INPUT -p tcp -m tcp --dport 80 --tcp-flags SYN,RST,ACK SYN -j ACCEPT
# FTP
-A HA-INPUT -p tcp -m tcp --dport 21 --tcp-flags SYN,RST,ACK SYN -j ACCEPT
# POP
-A HA-INPUT -d 10.10.10.100 -m tcp --dport 110 --tcp-flags SYN,RST,ACK SYN -j ACCEPT
# SMTP
-A HA-INPUT -d 10.10.10.100 -m tcp --dport 25 --tcp-flags SYN,RST,ACK SYN -j ACCEPT
# NameServers
-A HA-INPUT -p udp -m udp --sport 53 -j ACCEPT
# Reject
-A HA-INPUT -p tcp -m tcp --tcp-flags SYN,RST,ACK SYN -j REJECT --reject-with icmp-host-prohibited
-A HA-INPUT -p udp -m udp -j REJECT --reject-with icmp-host-prohibited
#-A HA-INPUT -p icmp -j REJECT --reject-with icmp-host-prohibited
COMMIT
Now you can start heartbeat:
# /etc/init.d/heartbeat start
#! /bin/bash
##############################
# IPVS Daemon Monitor Script
# Avatar
##############################
# Variables
clusip="10.10.10.100"
clusnet=`/sbin/ifconfig -a | grep $clusip | grep -v grep| wc -l`
# Ldirectord Check
if [ "$clusnet" -gt "0" ]; then
msps=`ps -ef | grep "ldirectord" | grep -v grep | wc -l`
if [ "$msps" -lt "1" ]; then
logger "NOT Running Ldirectord"
/etc/init.d/ldirectord start
fi
fi
# Connection Sync Daemon
if [ "$clusnet" -gt "0" ]; then
msps=`ps -ef | grep "ipvs_syncbackup" | grep -v grep | wc -l`
if [ "$msps" -eq "1" ]; then
logger "Active Node: Stopping Backup Daemon"
/sbin/ipvsadm --stop-daemon backup
fi
msps=`ps -ef | grep "ipvs_syncmaster" | grep -v grep | wc -l`
if [ "$msps" -lt "1" ]; then
logger "NOT Running Master"
/sbin/ipvsadm --start-daemon=master --mcast-interface=eth1
fi
else
msps=`ps -ef | grep "ipvs_syncbackup" | grep -v grep | wc -l`
if [ "$msps" -lt "1" ]; then
logger "NOT Running Slave"
/sbin/ipvsadm --start-daemon=backup --mcast-interface=eth1
fi
fi
# chmod +x /usr/local/bin/ldircheck
# crontab -l
* * * * * /usr/local/bin/ldircheck